
Summary
The resources allocation in Kubernetes is a complex mechanism. The Kubernetes Scheduler is the component in charge of matching the requested by the pod resources with the available in the cluster nodes. Setting the correct resources requests plays a crucial role in the QoS and the cluster costs. The infrastructure costs is a hot topic in the companies now during the crisis. See bellow for the detailed explanation.
Details
The kube-scheduler is the component which matches the resources asked by a Pod with the schedulable capacity.
As you can see in the Figure 1, the entire capacity of the cluster node is different from the schedulable capacity because the nodes have multiple other system processes on them which require the machine resources.
The requests values provided in the Pod manifest are used by the kube-scheduler to take the decision on which node to place the Pod.
In the picture bellow you can see graphical explanation of how the kube-scheduler decides to allocate nodes based on requests values.
The other important attribute is the limits values.
They are needed especially by the clusters hosting multiple workload profiles to avoid the noisy neighbour effect (in short - one application uses the machine resources entirely and the other applications located on the same machine are starving)
The limits values when reached:
will kill the pod in case of RAM (OOM in the status messages)
throttle down the pod CPU in case of CPU - the effect is an increasingly poor performance of the process inside the container.
The limits values are a must to have especially situations when the hosted applications are not stable and can leak resources, which in combination with auto scalers can eat your entire budget.
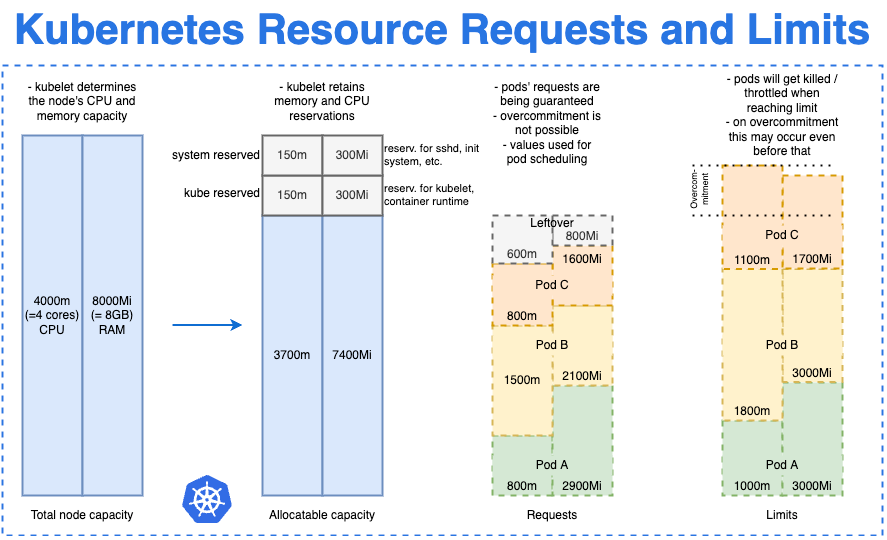
Figure 1. Credits go to https://shipit.dev/posts/kubernetes-overview-diagrams.html#resource-requests-and-limits
Quality of Service
How is the QoS ensured in K8s?
The following scenarios are possible:
Requests and Limits values are equal - the allocated resources are guaranteed. This is the best scenario you can have to latency critical applications.
Limits values are bigger than Request values - the allocated resources are burstable. This scenario works well with application which start with lower resources consumption and can increase them gradually over time.
No Requests and Limits values established - the resources are allocated at best effort. This works well when you don’t really care how the applications are going to work. You just them to finish doing some work.
K8s auto scalers and how that plays with the costs
Cluster Autoscaler
Cluster Autoscaler (CA) is triggered by the K8s scheduler to add/delete nodes into/from the cluster within the established CA limits.
Horizontal Pod Autoscaler
Horizontal Pod Autoscaler (HPA) uses the real consumption metrics (from the Metrics server) to change the Pod replicas number within the established HPA limits when the metric upper/lower threshold is reached.
Vertical Pod Autoscaler
Vertical Pod Autoscaler (VPA) uses the real consumption metrics (from the Metrics server) to increase/decrease the Pod requests value within the established VPA limits.
To reach the perfect costs distribution for a K8s cluster it’s crucial to enable both the scaling mechanisms and establish correct requests values for your workloads.
If you like my content, sign up now so you don’t miss the next issue.
In the meantime, tell your friends!
Very good explanation. thank you for the detailed info.